LEKCE 5.
Náplň lekce:
- Detailnější pohled na seznamy
- Vícehodnotové proměnné
- Vysvětlující příklady pro práci se seznamy
- Základní funkce pro práci se seznamy:length$ a member$
- Retract
- Příklady k procvičení
Detailnější pohled na seznamy
Seznam je určitá datová struktura, která může nabývat libovolného množství položek (může se jednat i o prázdný seznam). Pokud fakt obsahuje jen jednu hodnotu - jedná se o jednoduchý fakt. Jestliže obsahuje více hodnot - jedná se o seznam. Položky seznamu se oddělují mezerami. Záleží na Vás, jestli jednotlivé položky seznamu budou mít určité uspořádání např. seznam bude obsahovat soubor čísel od nejmenšího po největší (seznam_cisel 2 5 9 12 13 18 25) nebo bude seznam obsahovat libovolné položky bez vztahů (ovoce hruska jablko pomeranc kiwi)
Se seznamy resp. práce s nimi je spojen pojem vícehodnotová proměnná.Vícehodnotové proměnné
V předchozích příkladech jsme pracovali s takovými proměnnými, které mohly nabývat jen jedné hodnoty - např. ?ovoce - tato proměnná mohla nabývat jen hodnoty hruska nebo jablko nebo pomeranc, ale ne všechny tyto hodnoty najednou. Název už Vám mohl napovědět, že jsme dosud pracovali s tzv. jednohodnotovými proměnnými.
Příklady jednohodnotových proměnných:
(osoba Karel)
(zvire Pes) …
Existují ještě proměnné, které mohou nabývat více hodnot. Jedná se potom o tzv. vícehodnotové proměnné, které se označují takto: $?nazev_promenne. Znaky před nazvem_promenne jsou dolar a otazník. Tento druh seznamu se užívá např., když si nejste jisti kolik hodnot daný seznam má. Co se týká jejich použití v pravidlech, tak se v akční části pravidla používá tento zápis pro vícehodnotovou proměnnou ?nazev_promenne tj. bez dolaru. (doporučuje se ho v akční části nepoužívat, ale když ho zde užijete - nezjistila jsem, že by to byla nějaká výrazná chyba).
Příklady pro práci se seznamy (způsoby výpisů hodnot):
Příklad 1.
(stáhnout: zelenina_1.clp)Grafické vysvětlení činnosti programu zelenina_1.clp
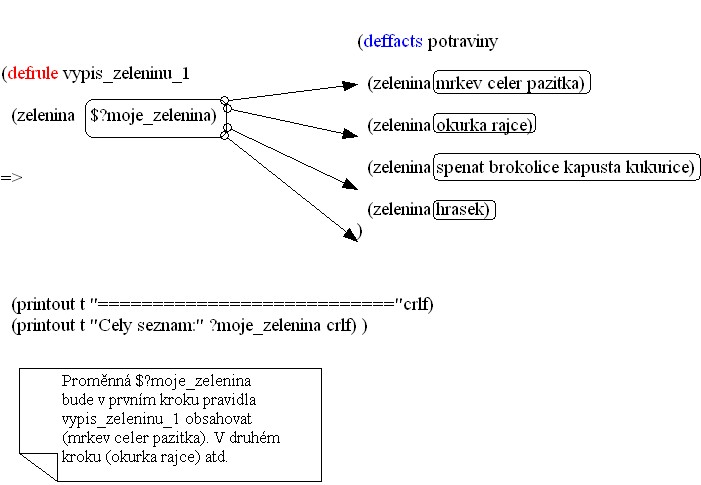
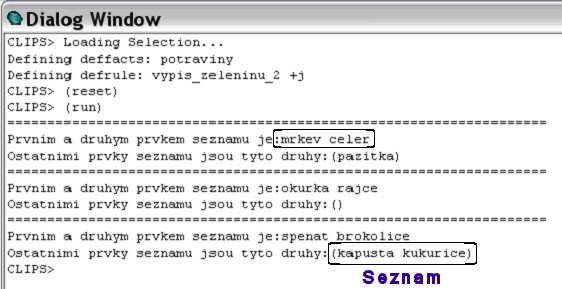
Příklad 2.
(stáhnout: zelenina_2.clp)Grafické vysvětlení činnosti programu zelenina_2.clp

Všimněte si, že výsledkem výpisu v Clipsu je seznam hodnot opatřený závorkami - tak můžete poznat, že jste pracovali s nějakým seznamem. Jestliže pracujete s jednohodnotovou proměnnou - není opatřena závorkami.
Příklad 3.
(stáhnout: zelenina_3.clp)Grafické vysvětlení činnosti programu zelenina_3.clp

Základní funkce pro práci se seznamy:
- length$: tato funkce zjistí délku seznamu - tedy počet prvků, které se v seznamu nacházejí.
syntaxe: (length$ $?muj_seznam) tj. název funkce a název vašeho seznamu, který u této funkce musí být vícehodnotovou proměnnou. - member$: tj. "je členem" tzn., že tato funkce ověří, jestli se určitý prvek nachází v určitém seznamu.
syntaxe: (member$ ?muj_prvkek $?muj_seznam)

RETRACT
Dalším příkazem, který nemusí být spojen jen s vícehodnotovými proměnnými, ale je spojen s fakty jako takovými je příkaz retract. S tímto příkazem jsme se setkali již dříve (lekce 4.). Slouží nám k odstraňování faktů z báze faktů. Proč bychom vůbec chtěli nějaký fakt odstranit? Například když chceme zabránit opakovanému vykonávání nějakého pravidla, nebo již daný fakt v programu nepotřebujeme. Praxe Vám ukáže, kdy je to vhodné a užitečné.Vysvětlující příklady příkazu retract:
(stáhnout: retract_1.clp)Princip retractu:
Každý fakt v naší bázi je jednoznačně identifikován pomocí tzv. identifikátoru. Jaký identifikátor má který fakt můžete zjistit v okně Facts (tak jak je to znázorněno na obrázku níže).
V příkladu retract_1.clp můžeme vidět, že např. seznam s oblíbenými zvířaty má identifikátor: f-2 apod. Kdybychom chtěli smazat seznam s oblíbenými zvířaty v bázi faktů, pak by stačilo zapsat jen do usuzovací části jeden příkaz (retract 2), kde číslo 2 by značilo daný identifikátor, ke kterému tento seznam patří. Kde ale máme jistotu, že seznam s oblíbenými zvířaty bude mít opravdu číslo identifikátoru 2. Nevíme totiž předem, jakou hodnotu identifikátoru bude mít daný fakt. Proto tento postup není vhodný.
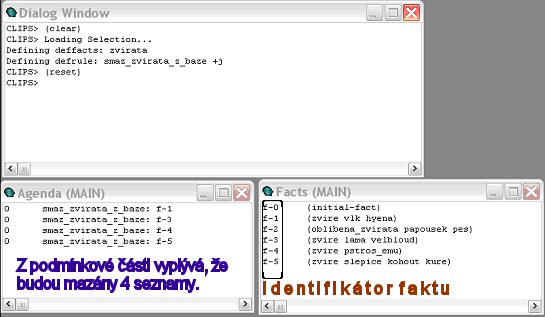
Lepším postupem pro smazání určitého faktu je ten následující. Vezměme si první podmínku z příkladu retract_1.clp.
Podmínková část:
?pryc_s_nimi<-(zvire $?nejaka_zvirata)
Touto metodou si vlastně zjišťujeme jaký identifikátor má fakt
(zvire $?nejaka_zvirata.) Toto číslo (identifikátor) si uložíme do proměnné ?pryc_s_nimi. Šipka Vám může naznačit "co jde kam". Identifikátor faktu (zvire $?nejaka_zvirata) si uložíme do proměnné ?pryc_s_nimi.
Poznámka: značka šipky je tvořena znaménkem menší a pomlčkou.
Usuzovací (akční část):
(retract ?pryc_s_nimi)